PHÂN TÍCH ẢNH HƯỞNG CỦA YẾU TỐ KHU VỰC VÀ NĂM LÊN MÔ HÌNH ĐÁNH GIÁ CHỈ SỐ HẠNH PHÚC
Author: Thang V.Le, Khoa D.Tran, Quang D.Hoang, Manh T.Nguyen, Tu D.Vo
1. Mở đầu
1.1. Đặt vấn đề
World Happiness Report là cuộc khảo sát về trạng thái hạnh phúc trên toàn cầu, xếp hạng 155 quốc gia và vùng lãnh thổ về mức độ hạnh phúc được báo cáo tại Liên Hợp Quốc vào sự kiện kỉ niệm ngày Quốc tế hạnh phúc hằng năm vào ngày 20 tháng 3. Kết quả của cuộc khảo sát này đang dần được công nhận rộng rãi ở nhiều chính phủ, tổ chức xã hội bởi vì dựa vào chỉ số hạnh phúc này họ có thể dễ dàng đưa ra các quyết định về chính sách chính trị xã hội. Ngoài ra chỉ số hạnh phúc còn được nhiều chuyên gia thuộc nhiều lĩnh vực khác nhau như kinh tế, tâm lí học, phân tích thống kê, chính sách xã hội, ... sử dụng để đánh giá sự tiến bộ của một quốc gia. Chỉ số này được đánh giá dựa trên câu trả lời của những câu hỏi về chất lượng cuộc sống trong cuộc khảo sát, những câu hỏi này được đánh giá theo thang đo Cantril ( thang đo chất lượng cuộc sống ) từ 0 đến 10 điểm. Điểm số này được khảo sát từ một mẫu đại diện cho khu vực, có 6 yếu tố chính ảnh hưởng đến chỉ số hạnh phúc là: sản xuất kinh tế, hỗ trợ xã hội, tuổi thọ, sự tự do, tỉ lệ tham nhũng và sự hào phóng.
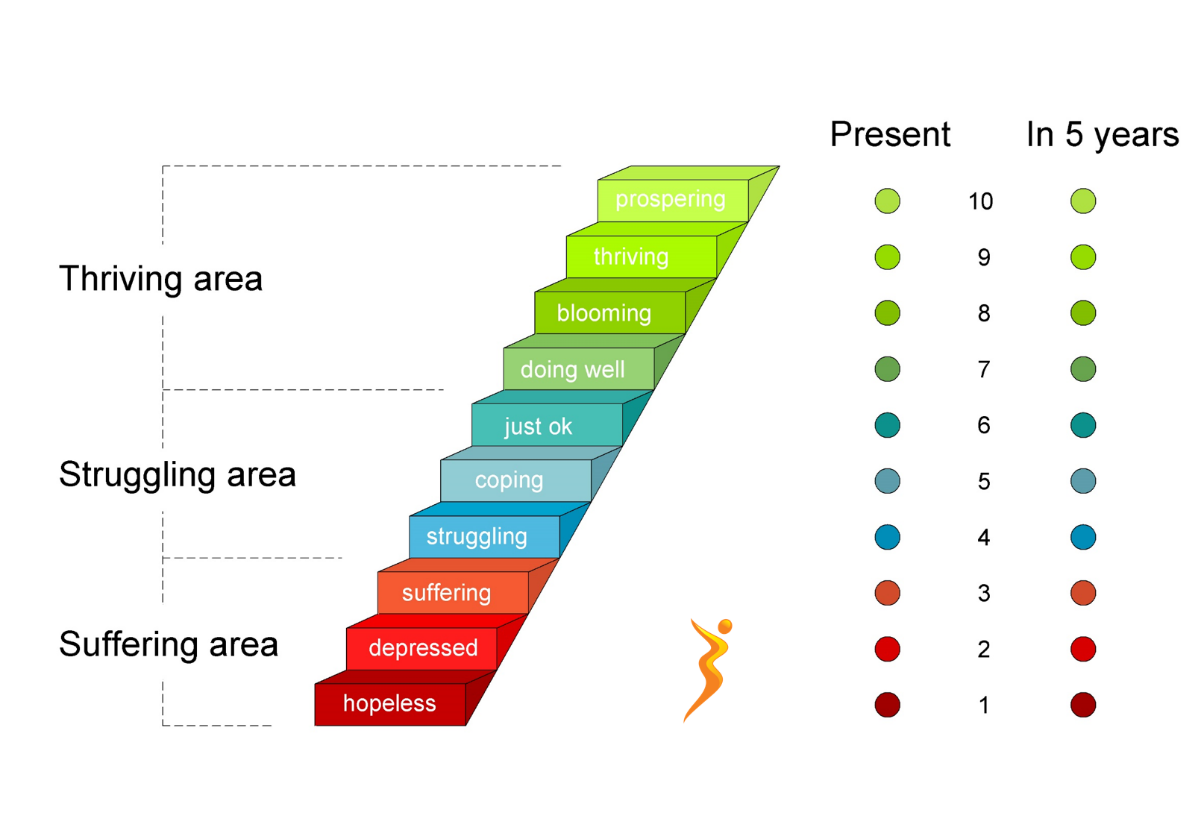
Hình 1.1 Biểu diễn thang do Cantril
Từ đây ta có thể đặt ra giả thiết rằng liệu có hay không những yếu tố khác tác động lên chỉ số hạnh phúc của một quốc gia ? Lấy ví dụ năm 2020 là một năm đáng quên đối với nền kinh tế toàn cầu vì dịch bệnh COVID – 19, liệu những quốc gia phòng chống dịch tốt có cải thiện được chỉ số hạnh phúc của quốc gia mình không ?
1.2. Mục tiêu nghiên cứu
- Phân tích ảnh hưởng của 2 yếu tố đó là khu vực và năm lên chỉ số hạnh phúc của một quốc gia.
- Trả lời cho giả thiết liệu rằng ảnh hưởng của 2 yếu tố này là độc lập hay giữa 2 yếu tố có sự tương tác với nhau ảnh hưởng đến chỉ số hạnh phúc.
- Xây dựng mô hình hồi quy và so sánh kết quả mô hình dự đoán so với mô hình sử dụng 6 yếu tố chính cấu thành chỉ số hạnh phúc.
1.3. Đối tượng nghiên cứu
Đối tượng chính được dùng để phân tích nghiên cứu chính trong bài là dựa trên bộ dữ liệu World Happiness Report của 3 năm 2015, 2016, 2017.
Bảng 2.1 Codebook mô tả dữ liệu
|
Thông tin |
Nội dung |
|
Tên bộ dữ liệu |
World Happiness Report |
|
Nguồn thu thập và cách thức thu thập |
Nguồn thu thập: Gallup World Poll Cách thức thu thập: Thực hiện khảo sát từ nhiều quốc gia |
|
Kích thước bộ dữ liệu |
Bộ dữ liệu gồm 3 files khác nhau của các năm 2015, 2016, 2017 của 155 quốc gia và vùng lãnh thổ. Số thuộc tính: 7 |
|
Thông tin tên các thuộc tính |
- Country: Tên quốc gia - Region: Khu vực của quốc gia đó ( Southeastern Asia, North America, ...) - Happiness Rank: Xếp hạng chỉ số hạnh phúc của quốc gia - Happiness Score: Chỉ số hạnh phúc của quốc gia - Economy ( GDP per capita ): Thu nhập bình quân đầu người - Family: Chỉ số gia đình - Health ( Life expectancy ): Tuổi thọ trung bình - Freedom: Mức độ tự do của quốc gia - Trust ( Government Corruption ): Mức độ tin tưởng vào chính phủ - Generosity: Độ hào phóng của người dân |
- 2. Tiến hành thực nghiệm
2.1. Tiền xử lí dữ liệu
Vì đây là dữ liệu quan trọng của Liên Hợp Quốc nên chất lượng dữ liệu đã tốt sẵn. Để thuận tiện cho việc trực quan dữ liệu chúng ta chỉ cần chỉnh sửa tên các khu vực về dạng key như bảng sau:
Bảng 2.2 Tên khu vực và kí hiệu biểu diễn
|
Tên khu vực |
Key |
|
Australia and New Zealand |
ANZ |
|
Central and Eastern Europe |
CEE |
|
Eastern Asia |
EA |
|
Latin America and Caribbean |
LAC |
|
Middle East and Northern Africa |
MNA |
|
North America |
NA |
|
Southeastern Asia |
SEA |
|
Southern Aisa |
SA |
|
Sub-Saharan Africa |
SSA |
|
Western Europe |
WE |
Sau đó tiến hành gộp 3 file dữ liệu của 3 năm 2015, 2016 và 2017 để có thêm được thuộc tính năm.
2.2. Thăm dò và trực quan hóa dữ liệu
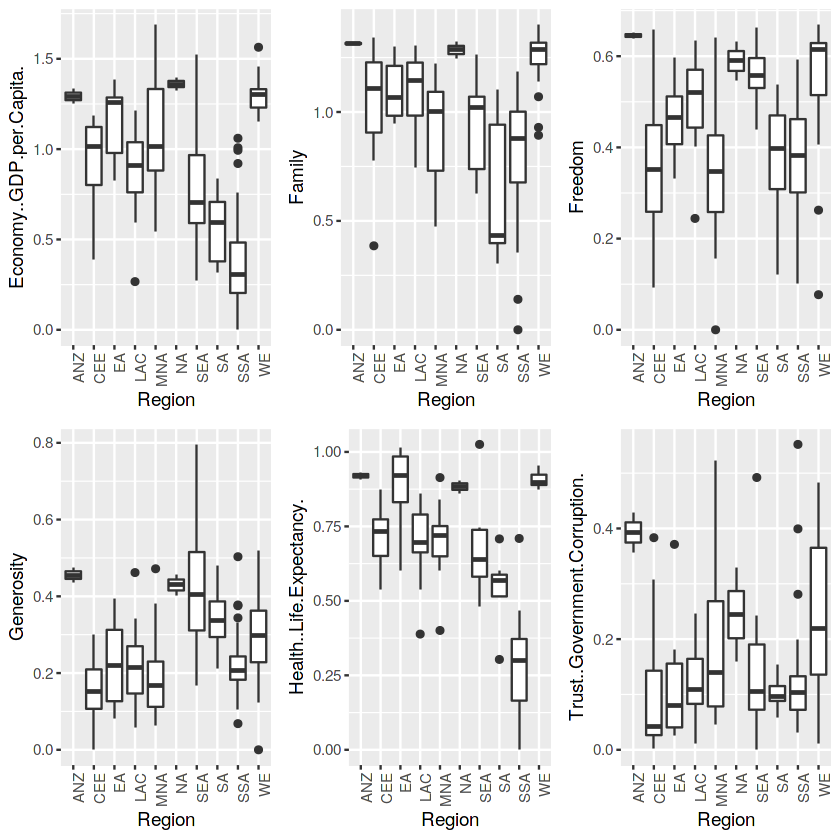
Hình 2.1 Boxplot ảnh hưởng của từng khu vực lên từng thuộc tính
(Ở hình trên ta có thể thấy ở từng thuộc tính, dữ liệu phân bố không đều và có xuất hiền một số ouliers, một số quốc gia có phương sai dữ liệu lớn, một số khác thì phương sai dữ liệu nhỏ. )
Để giải thích cho vì sao lại có sự khác nhau về phương sai giữa các khu vực, ta hãy xem số lượng quốc gia trong mỗi khu vực ở hình 3.2. Ở đây ta có thể thấy vì số lượng quốc gia trong khu vực khác nhau và chênh lệch rõ rệt, ví dụ như NA (Bắc Mĩ ) và SSA ( vùng châu phi gần đại sa mạc Sahara) tuy NA, có số lượng quốc gia chỉ là 2 (Canada và Mĩ) do đó khoảng phương sai của NA không rộng so với SSA có 40 quốc gia, tuy nhiên trung vị của NA có chỉ số cao hơn hẳn vì đây là những quốc gia phát triển mạnh.
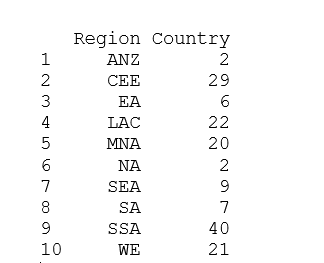
Hình 2.2 Số lượng quốc gia trong mỗi khu vực
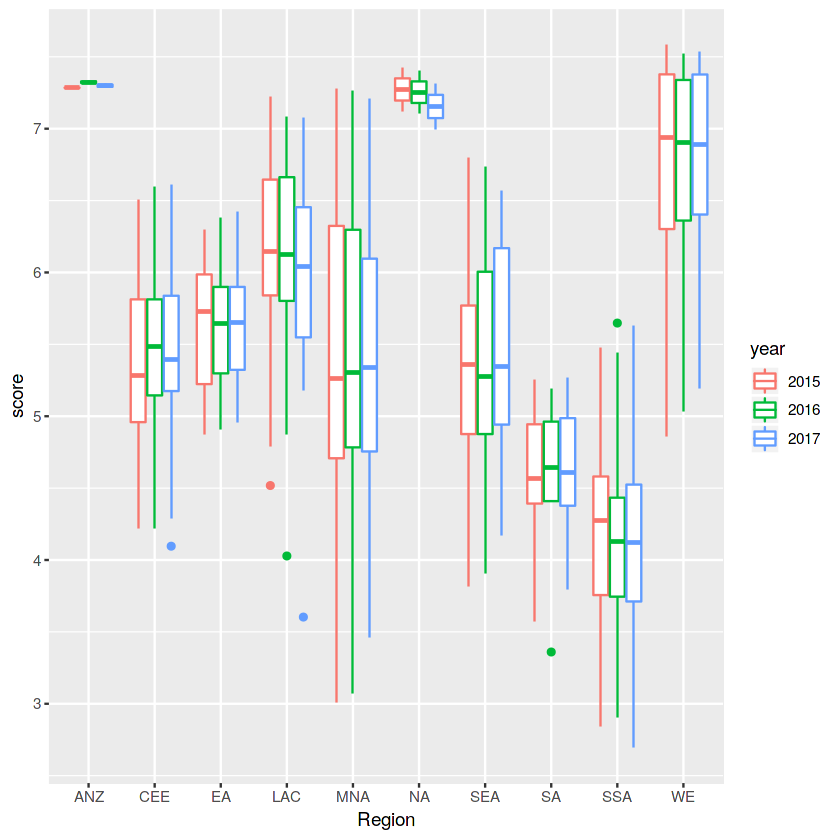
Hình 2.3 Boxplot ảnh hưởng của yếu tố khu vực và năm lên chỉ số hạnh phúc
(Dựa vào hình 3.3 ta có thể thấy sự thay đổi chỉ số hạnh phúc giữa các năm không đáng kể. Nhưng giữa từng khu vực khác nhau thì có sự chênh lệch . Ở đây ta có thể ngầm suy luận rằng yếu tố năm không ảnh hưởng nhiều đến chỉ số hạnh phúc.)
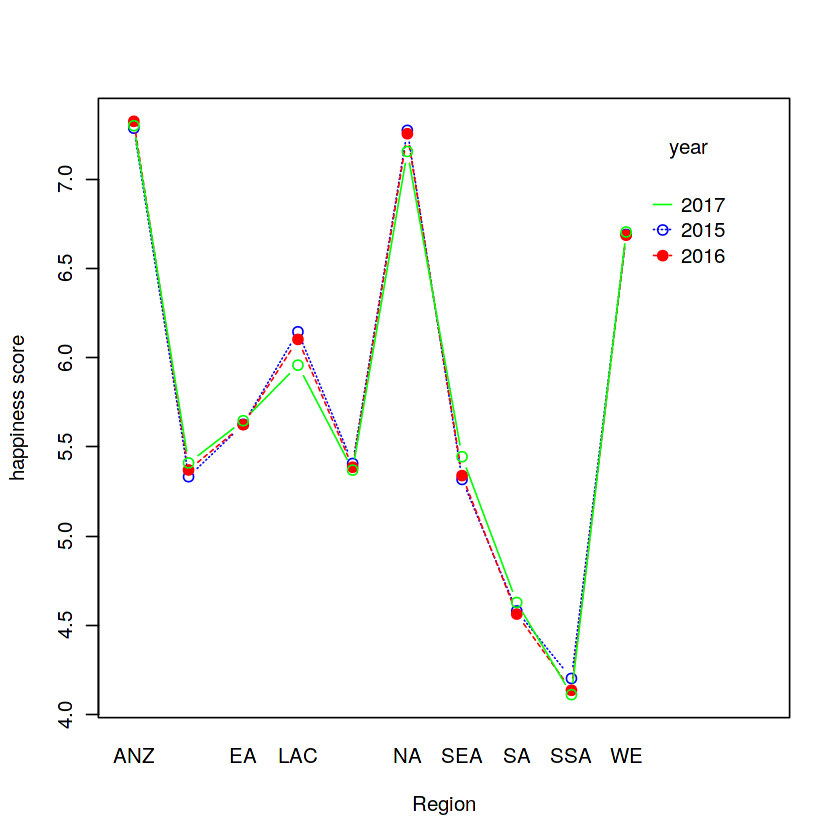
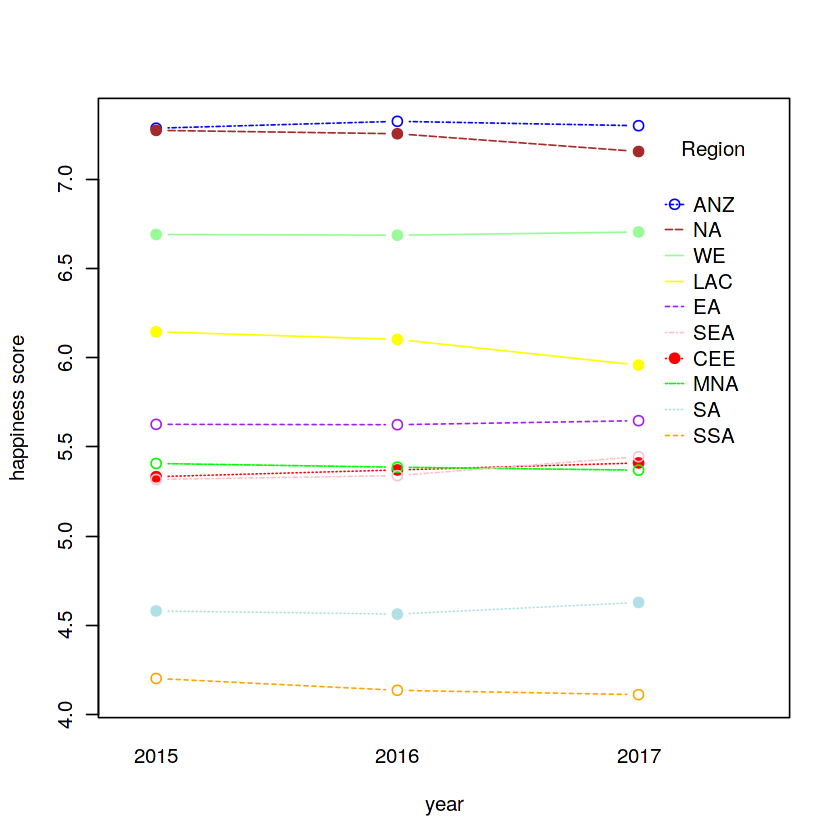
Hình 2.4 Plot ảnh hưởng của yếu tố khu vực ( Region ) và năm (year) lên chỉ số hạnh phúc.
(Hình 2.4 bên trái, các vùng và chỉ số hạnh phúc qua các năm có sự tương tác với nhau rất nhiều. Tuy nhiên qua hình 2.4 bên phải thì năm và chỉ số hạnh phúc qua các vùng là các đường song song vói nhau, không có sự tương tác mạnh. Điều này củng cố thêm cho giả thiết yếu tố năm không có nhiều ảnh hưởng đến chỉ số hạnh phúc đã đưa ra ở hình 2.3)
2.3. Phân tích ANOVA
Tiến hành sử dụng phương pháp phân tích ảnh hưởng của 2 yếu tố khu vực và năm lên chỉ số hạnh phúc trong 2 trường hợp:
2.3.1. Giữa khu vực và năm có sự tương tác với nhau
Ta có 2 giả thiết đặt ra cho phân tích
H0: Không có tương tác giữa khu vực và năm
H1: Có tương tác giữa khu vực và năm
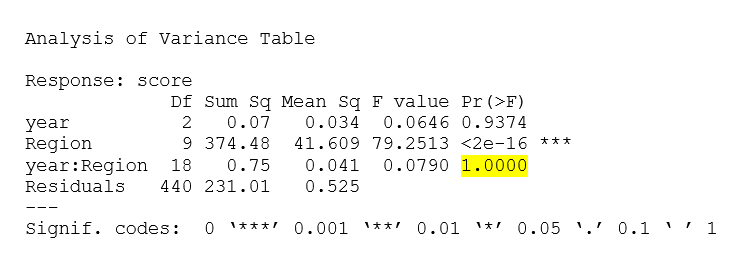
Hình 2.5 Kết quả phân tích ANOVA trong trường hợp khu vực và năm có tương tác với nhau.
Ở hình trên, ta thấy giá trị P-value tại tương tác year: Region có giá trị bằng 1 do đó ta chấp nhận H0 - giữa khu vực và năm không có sự tương tác lẫn nhau ảnh hưởng đến chỉ số hạnh phúc
2.3.2. Giữa khu vực và năm không có tương tác
Giữa khu vực và năm không sự tương tác với nhau
Ở phân tích này, ta đặt ra giả thiết cho ảnh hưởng của từng yếu tố lên chỉ số hạnh phúc :
H0A: năm không ảnh hưởng lên chỉ số hạnh phúc
H1A: năm có ảnh hưởng lên chỉ số hạnh phúc
Và
H0B: khu vực không ảnh hưởng lên chỉ số hạnh phúc
H1B: khu vực ảnh hưởng lên chỉ số hạnh phúc
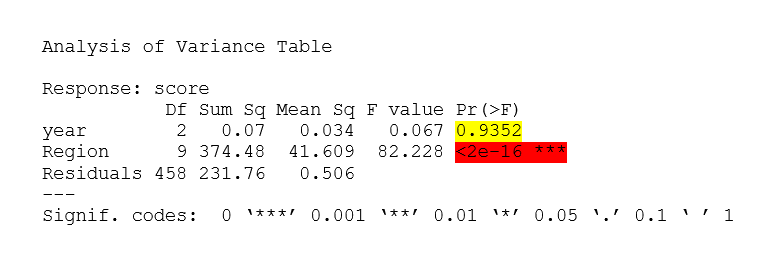
Hình 2.6 Kết quả phân tích ANOVA của yếu tố khu vực và năm lên chỉ số hạnh phúc
Ta thấy giá trị P-value của yếu tố năm có giá trị 0.9352 > mức ý nghĩa. Do đó chấp nhận H0A – năm không ảnh hưởng lên chỉ số hạnh phúc. Điều này cũng đúng với giả thiết đặt ra ở trên khi thăm dò và trực quan hóa dữ liệu.
Ngược lại, giá trị P-value của yếu tố khu vực mang giá trị rất nhỏ 2e-16 vì vậy chấp nhận H1B - yếu tố khu vực ảnh hưởng lên chỉ số hạnh phúc.
2.4. Sử dụng phương pháp Tukey HSD để gom nhóm các khu vực
Sau khi xác định được khu vực là yếu tố duy nhất ảnh hưởng đến chỉ số hạnh phúc, ta sử dụng phương pháp Tukey HSD để kiểm tra ý nghĩa thống kê của sự khác biệt giữa các cặp khu vực nhẳm mục đích gom cụm các khu vực tương đồng nhau giảm bớt nhiễu cho yếu tố khu vực.
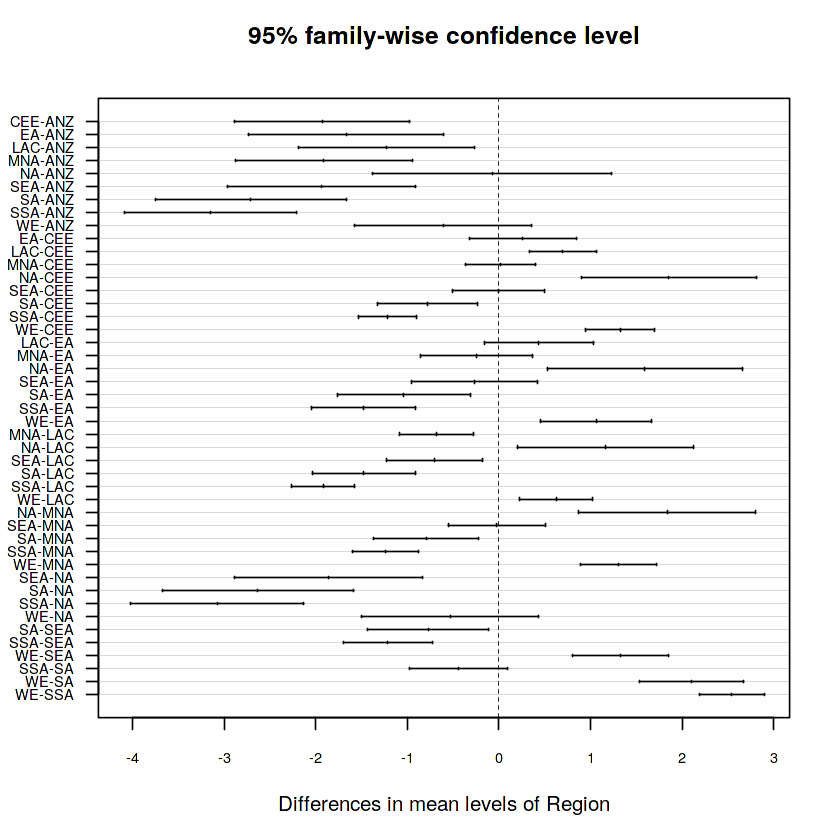
Hình 2.7 Kết quả sử dụng phương pháp Tukey HSD để kiểm tra sự khác nhau giữa các khu vực với độ tin cậy 95%
Dựa vào kết quả phân tích, ta có thể thấy có 11 cặp khu vực mà sự khác nhau không mang ý nghĩa thống kê (có quan hệ với nhau ) là: NA-ANZ, WE-ANZ, EA-CEE, MNA-CEE, SEA-CEE, LAC-EA, MNA-EA, SEA-EA, SEA-MNA, WE-NA, SSA-SA.
Dựa vào tính chất bắc cầu ta có thể gom 11 cặp này thành 3 cụm
NA - ANZ - WE (Cụm 1)
EA - CEE - MNA - SEA - LAC (Cụm 2)
SSA - SA (Cụm 3)
Sau đó tiếp tục sử dụng phương pháp Tukey HSD để kiểm tra lại các cụm này (H 3.8) thì nhận thấy sự khác biệt giữa các cụm này đã hoàn toàn mang ý nghĩa thống kê ( không chứa 0 )
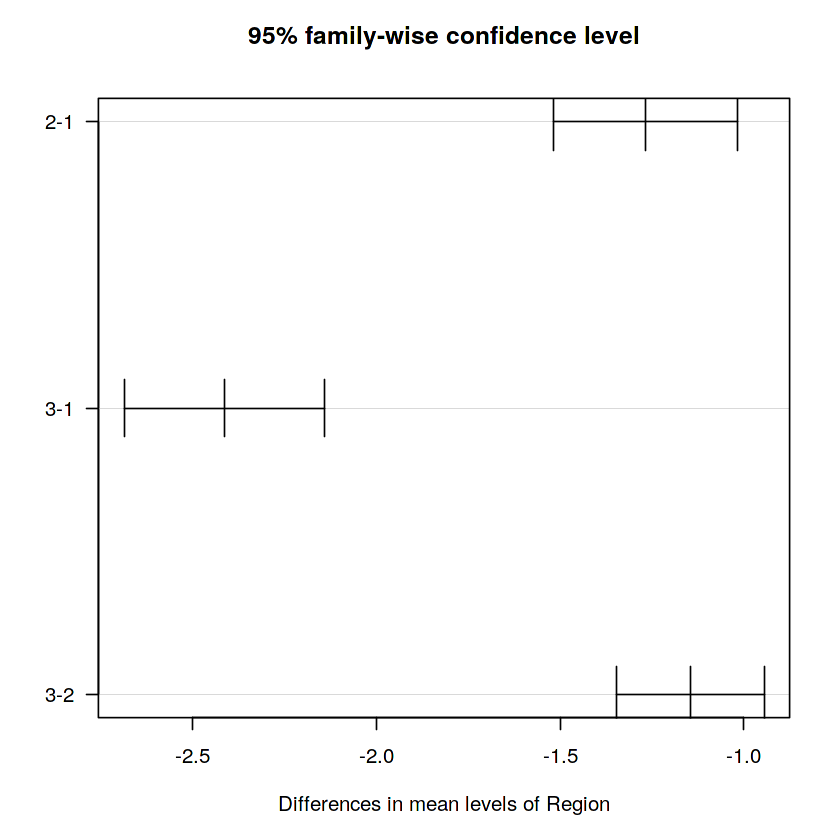
Hình 2.8 Sử dụng phương pháp Tukey HSD để phân tích 3 cụm khu vực
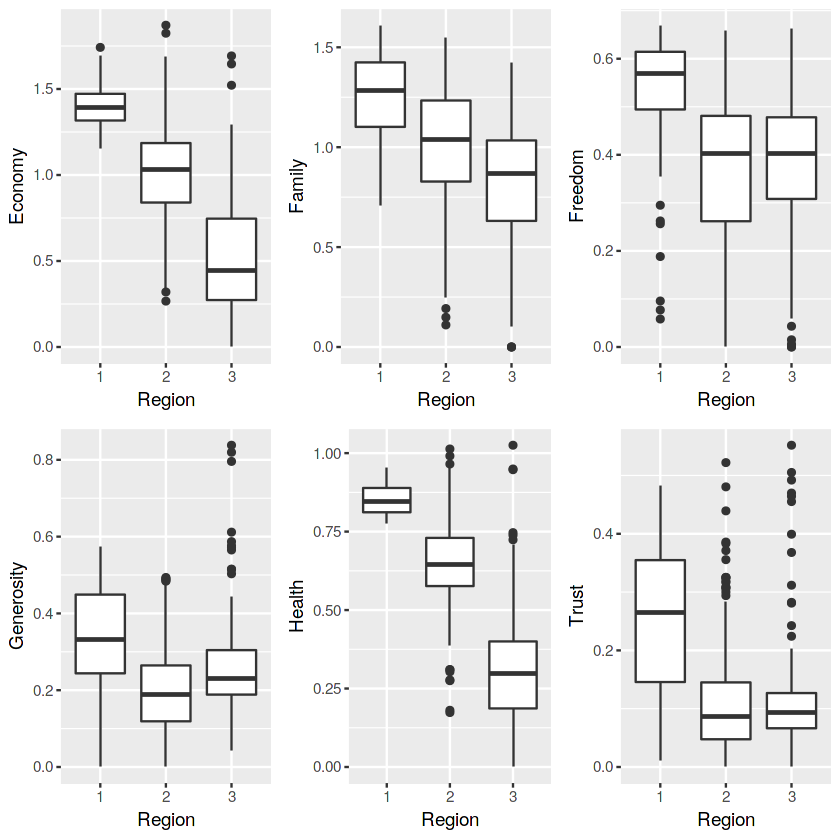
Hình 2.9 Boxplot ảnh hưởng của từng cụm lên từng yếu tố
Ở hình trên, ta có thể thấy các khu vực sau khi chia cụm ảnh hưởng rõ ràng hơn so với các khu vực riêng lẻ (H 2.1). Cụm 1 là cụm luôn có các chỉ số cao hơn các cụm khác. Để làm rõ cho điều này ta hãy cùng quan sát bản đồ thế giới thể hiện quốc gia của các cụm ở Hình 3.10. Ta có thể thấy Cụm 1 là tập hợp của những quốc gia lớn như Canada, Mĩ , Australia, các nước Đông Âu. Cụm 2 là các nước châu Á và châu Mĩ Latin, Cụm 3 là Ấn độ và các nước châu Phi – lí giải cho lí do tại sao cụm 3 lại có các chỉ số thấp hơn các cụm còn lại. Tuy nhiên ở chỉ số độ hào phóng (Generosity) thì cụm 2 lại có giá trị trung vị và phương sai thấp hơn cụm 3.
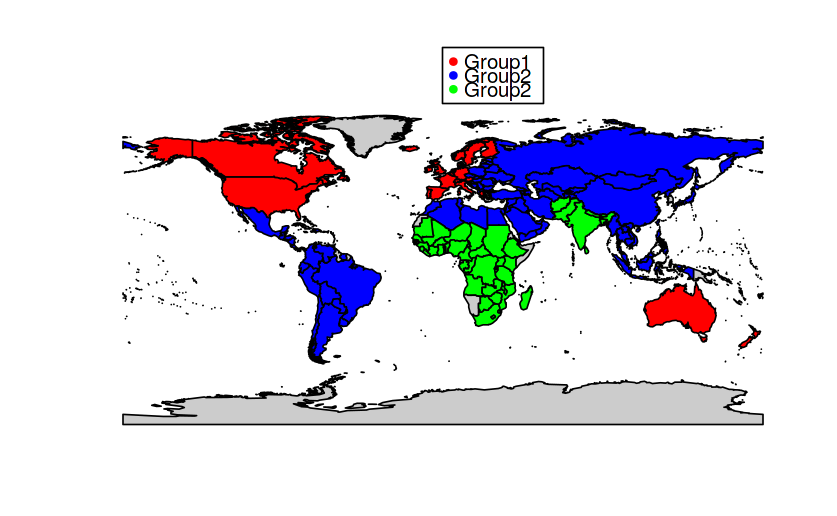
Hình 2.10 Biểu diễn các cụm lên bản đồ thế giới
2.5. Xây dựng mô hình hồi quy dự đoán chỉ số hạnh phúc
2.5.1. Thực nghiệm 1
Xây dựng mô hình hồi qui tuyến đính đa biến dự đoán chỉ số hạnh phúc (Happiness Score) dựa vào 6 yếu tố: Economy, Family, Health, Freedom, Trust, Generosity.
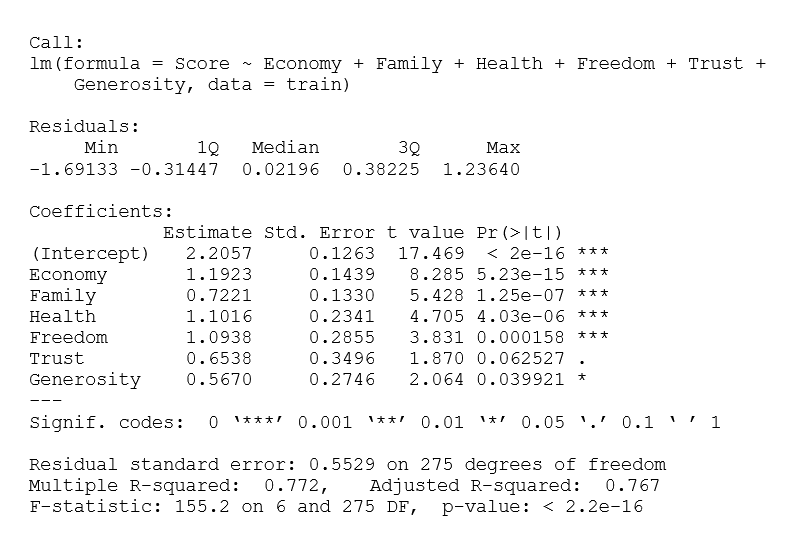
Hình 2.11 Kết quả mô hình hổi quy của thực nghiệm 1
Từ kết quả trên, ta có thể đứa ra phương trình mô hình như sau:
Happiness Score = 2.2057 + 1.1923*Economy + 0.7221*Family + 1.1016*Health + 1.0938*Freedom + 0.6538*Trust + 0.5670*Generosity
2.5.2. Thực nghiệm 2
Sử dụng 7 yếu tố: Economy, Family, Health, Freedom, Trust, Generosity và Region (chưa gom cụm và không có tương tác giữa các yếu tố trên) để xây dựng mô hình dự đoán.

Hình 2.12 Kết quả mô hình hổi quy của thực nghiệm 2
(Đối với yếu tố Region, nhóm sử dụng label encoder để biến đổi các Region từ 0 – 9 tương ứng với 10 Region và đổi tên thành Region_Key)
Từ kết quả trên, ta có thể đứa ra phương trình mô hình như sau:
Happiness Score = 2.236782 + 1.194430*Economy + 0.718032*Family + 1.074365*Health + 1.110797*Freedom + 0.684045*Trust + 0.588831*Generosity – 0.004717*Region
2.5.3. Thực nghiệm 3
Tương tự mô hình 2 ở trên thì mô hình này ta sẽ sử dụng yếu tố khu vực đã được phân chia thành 3 cụm để xây dựng mô hình.
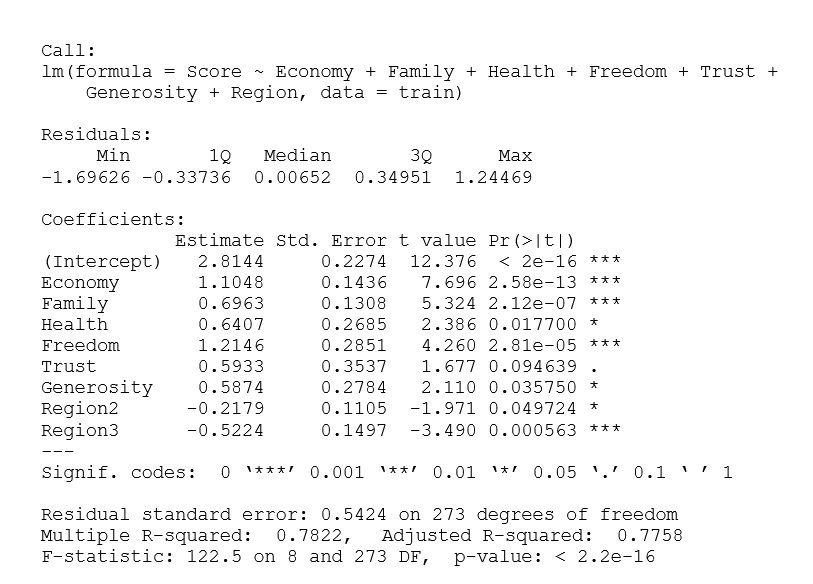
Hình 2.13 Kết quả mô hình hổi quy của thực nghiệm 3
(Sau khi encode Region vào 3 cụm có tên là 1, 2, 3 ở 3.4 thì khi đưa vào mô hình hồi quy, Region sẽ được Onehot Encode lại 1 lần nữa thành 2 cột là Region 2 và Region 3 tương ứng với thông tin ở 2 cột là 0,0 – Region 1, 1,0 – Region 2 và 0,1 Region 3)
Từ kết quả trên, ta có thể đứa ra phương trình mô hình như sau:
Happiness Score = 2.8144 + 1.1048*Economy + 0.6963*Family + 0.6407*Health + 1.2146*Freedom + 0.5933*Trust + 0.5884*Generosity – 0.2179*Region2 – 0.5224*Region3
2.5.4. Thực nghiệm 4
Giống với mô hình 3, nhưng ở đây ta cho phép các yếu tố sử dụng có sự tương tác với nhau.
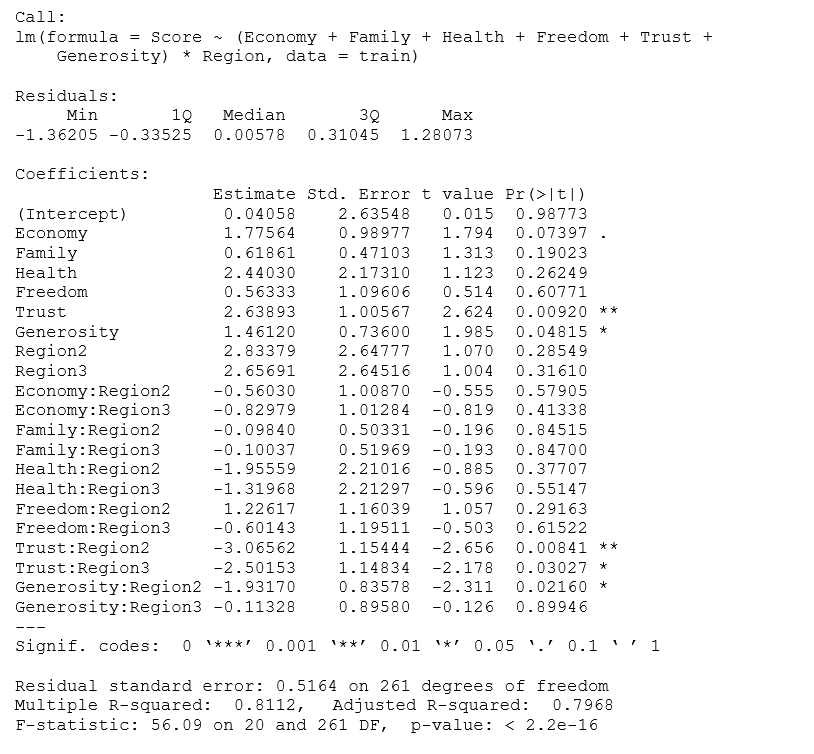
Hình 2.14 Kết quả mô hình hổi quy của thực nghiệm 4
Từ kết quả trên, ta có thể đứa ra phương trình mô hình như sau:
Happiness Score = 0.44058 + 1.77564*Economy + 0.61861*Family + 2.44030*Health + 0.56333*Freedom + 2.62893*Trust + 1.46120*Generosity + 2.83379*Region2 + 2.65691*Region3 – 0.56030*Economy*Region2 – 0.82979*Economy*Region3 – 0.09840*Family*Region2 – 0.10037*Family*Region3 – 1.95559*Health*Region2 – 1.31968*Health*Reion3 + 1.22617*Freedom*Region2 – 0.60143*Freedom*Region3 – 3.06562*Trust*Region2 – 2.50153*Trust*Region3 – 1.93170*Gererosity*Region2 – 0.11328*Generosity*Region3
2.5.5. So sánh kết quả thực nghiệm và nhận xét
Từ kết quả 4 thực nghiệm trên, ta sẽ vẽ biểu đồ để so sánh 4 mô hình hồi qui:
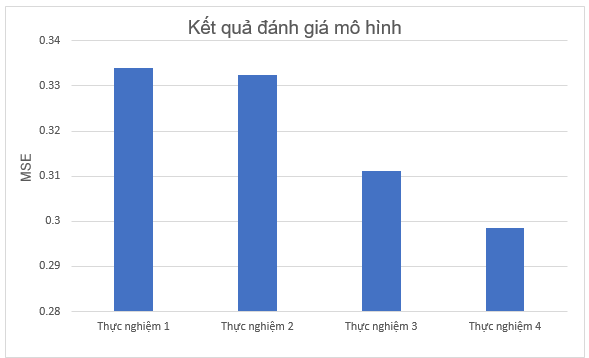
Hình 2.15 Kết quả đánh giá mô hình của 4 thực nghiệm theo độ đo MSE
Từ hình 2.15, ta có thể thấy yếu tố khu vực có ảnh hưởng tích cực lên mô hình dự đoán chỉ số hạnh phúc, đồng thời việc phân chia các cụm có mối quan hệ với nhau giúp chúng ta giảm thiểu dữ liệu nhiễu và giúp mô hình cải thiện kết quả đáng kể ở thực nghiệm 3.
Với việc kết hợp tương tác giữa các yếu tố với nhau sẽ cải thiện độ chính xác của mô hình một lần nữa so với chỉ phân cụm yếu tố khu vực. Tuy nhiên điều này sẽ làm tăng tính toán trong mô hình. Ta nên cân nhắc sử dụng trong mô hình với dữ liệu lớn và có nhiều yếu tố hơn.
- 3. Kết luận và hướng phát triển
3.1. Kết luận
- Thông qua đồ án môn học DS304, nhóm đã thực hiện thành công sử dụng phương pháp phân tích phương sai ANOVA để phân tích ảnh hưởng của 2 yếu tố khu vực và năm lên chỉ số hạnh phúc.
- Xây dựng mô hình hồi quy tuyến tính đa biến đề dự đoán chỉ số hạnh phúc dựa theo 6 yếu tố chính là Economy, Family, Health, Freedom, Trust và Generosity và mô hình kết hợp yếu tố khu vực có tương tác lẫn không có tương tác giữa các yếu tố.
- Cải thiện kết quả dự đoán của mô hình bằng cách sử dụng phương pháp Tukey HSD để gom cụm các khu vực có mối quan hệ với nhau.
3.2. Hướng phát triển
- Có thể cải thiện mô hình bằng những mô hình khác có độ phức tạp cao hơn như Polynomial Regression, Lasso Regression,... hoặc một số ensemble model khác.
- Sử dụng phương pháp phân tích thành phần chính PCA để loại bỏ một số yếu tố tương tác không cần thiết.
- 4. Tài liệu tham khảo
Biostatistics/Statistics 533.2008.Lecture21. InTheory of Linear Models.
http://courses.washington.edu/b533/lect21.pdf
Manolis Stratakis - Cantril Ladder: A first step towards improving drastically your Quality of Life… (2019)
https://innobatics.com/cantril-ladder/
Haynes W. (2013) Tukey’s Test. In: Dubitzky W., Wolkenhauer O., Cho KH., Yokota H. (eds) Encyclopedia of Systems Biology. Springer, New York, NY