Hội nghị MAPR 2020
ỨNG DỤNG CÔNG NGHỆ GIS VÀ VIỄN THÁM XÂY DỰNG BẢN ĐỒ TIỀM NĂNG LŨ QUÉT TỈNH QUẢNG TRỊ
ỨNG DỤNG CÔNG NGHỆ GIS VÀ VIỄN THÁM XÂY DỰNG BẢN ĐỒ TIỀM NĂNG LŨ QUÉT TỈNH QUẢNG TRỊ
Trần Võ Tấn Tài, Lê Thị Thiệp, Nguyễn Thị Phương Quyên
Những năm gần đây, nhiều cơn bão, lũ lụt, các trận lũ quét cuốn trôi nhà cửa, tài sản, làm nhiều người thiệt mạng và gián đoạn hoạt động sản xuất, nhất là ở các tỉnh miền trung nước ta. Lũ quét được hình thành do tổng hợp nhiều nhân tố gây nên như: đặc điểm địa hình, kết cấu đất, lớp phủ thực vật, lượng mưa,... Diện tích rừng đầu nguồn bị suy giảm và biến đổi khí hậu làm cho lũ quét xảy ra thường xuyên và khó dự báo hơn. Vì vậy, công tác dự báo, phòng chống lũ quét đóng vai trò quan trọng trong việc giảm thiểu thiệt hại.
Hiện nay hệ thống thông tin địa lý và viễn thám được sử dụng rộng rãi trong nhiều lĩnh vực trong đó có cảnh báo thiên tai. Mục đích của việc nghiên cứu là kết hợp công nghệ viễn thám và GIS với chỉ số tiềm năng lũ quét (FFPI) phân vùng nguy cơ lũ quét tỉnh Quảng Trị.
Tỉnh Quảng Trị thuộc vùng Bắc Trung Bộ. Địa hình núi cao thấp dần từ Tây sang Đông; mưa tập trung theo mùa; mật độ sông suối dày đặc, độ dốc lớn; ngoài ra, diện tích rừng bị suy giảm ở một số khu vực do các hoạt động sinh hoạt động sinh hoạt của con người (khai thác gỗ, mở rộng nông nghiệp,...). Với các đặc điểm tự nhiên trên làm cho Quảng Trị là nơi dễ xảy ra lũ quét. Hơn nữa, kinh tế - xã hội tỉnh Quảng Trị đã có bước phát triển rất rõ rệt, tuy nhiên nền kinh tế còn phụ thuộc nhiều vào nông nghiệp, đời sống vẫn còn nhiều khó khăn. Vì vậy, những tác động từ lũ quét ảnh hưởng nặng nề đến đời sống người dân ở nhiều khía cạnh (tính mạng, tài sản, tinh thần,...).
Nội dung của nghiên cứu gồm: Để xây dựng bản đồ tiềm năng lũ quét tỉnh Quảng Trị tiến hành thu thập các dữ liệu và sử dụng phương pháp GIS và viễn thám để xử lí ảnh vệ tinh và phân cấp FFPI (Greg Smith, 2010) cho từng nhân tố thành phần: độ dốc, loại đất, hiện trạng sử dụng đất, độ tàn che rừng, lượng mưa phân bổ. Mỗi lớp dữ liệu sẽ được gán giá trị FFPI từ 1 đến 10, giá trị nhỏ nhất là 1, giá trị lớn nhất là 10. Mỗi thành phần được gắn vào mô hình có trọng số và chồng xếp để ra được bản đồ tiềm năng lũ quét. Giá trị nhỏ nhất là 1 tương ứng với khu vực ít chịu ảnh hưởng nhất và giá trị lớn nhất là 10 tương ứng với khu vực có tiềm năng xảy ra lũ quét cao nhất.
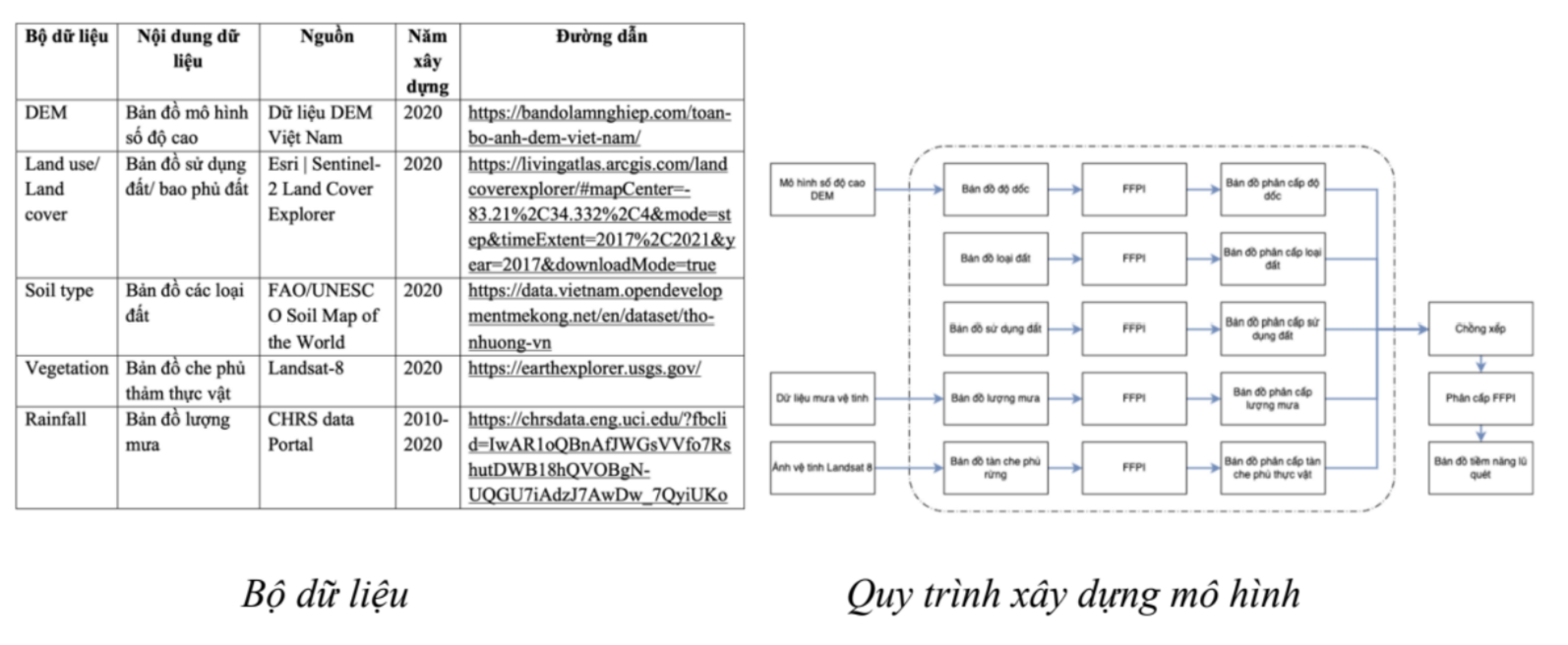
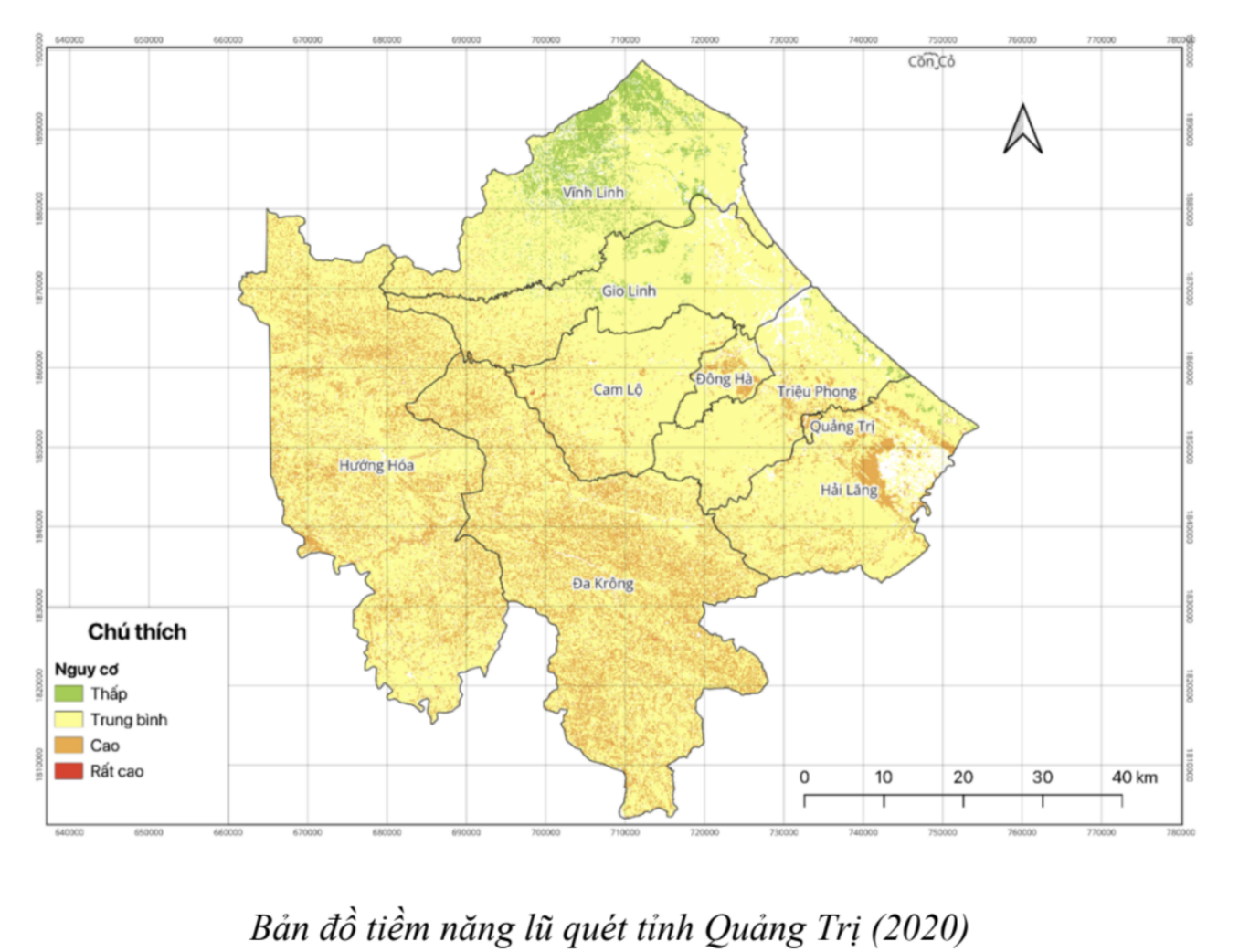
Bản đồ tiềm năng nguy cơ lũ quét tỉnh Quảng Trị được thành lập với 4 mức độ nguy cơ: rất cao, cao, trung bình, thấp. Kết quả phân vùng nguy cơ lũ quét trong tỉnh cho thấy trong 7 huyện và 2 thị xã, trong đó vùng có nguy cơ lũ quét cao hầu hết tại các huyện Đa Krông, Cam Lộ, Hướng Hoá, Hải Lăng. Tổng diện tích của các huyện nằm trong vùng lũ quét rất cao và cao chiếm hơn 20% tổng điện tích toàn tỉnh, đây là những huyện có địa hình núi cao, dốc lớn, phân cắt mạnh, điều kiện đi lại hết sức khó khăn và rất dễ bị cô lập, có nền thổ nhưỡng dạng đất xám nhưng chứa nhiều đất sét khó thấm nước, tán rừng thưa, lượng mưa trung bình tháng khá lớn. Cụ thề: Các huyện phía Tây Đa Krông (383,5 km2), Cam Lộ (30,1 km2), Hướng Hoá (259,8 km2) và vùng ven biển phía Đông Nam Hải Lăng (383,5 km2). Đối với các khu vực có nguy cơ thấp như là Vĩnh Linh, Gio Linh, phía Đông Bắc Cam Lộ, Triệu Phong, Quảng Trị.
Hiện tại, bản đồ đã cung cấp một đánh giá tương đối về các khu vực có nguy cơ xảy ra lũ quét. Tuy nhiên, độ chính xác của nó vẫn còn hạn chế do phụ thuộc chủ yếu vào dữ liệu có sẵn vì không có khả năng đo đạt thông tin thực tế. Nhưng vẫn cho cái nhìn tổng quát về các khu vực có thể xảy ra lũ quét trong tương lai nhằm thực hiện các biện pháp phòng chống và giảm nhẹ thiên tai, góp phần ổn định cuộc sống của cộng đồng.
Trân trọng.
Vector, Raster và bài toán dự đoán Land-use, Land-cover
Vector, Raster và bài toán dự đoán Land-use, Land-cover
Phạm Quốc Cường (20521150) - Nguyễn Văn Chọn (20521138) - Lê Khánh Châu (20521125)
Hiện nay, hệ thống thông tin địa lý đang được áp dụng vào nhiều lĩnh vực đặc biệt là trong GIS (Geographic Information Systems). Có 2 loại dữ liệu thường được sử dụng xuyên suốt đối với các nhà nghiên cứu về ứng dụng GIS 3D đó là dạng dữ liệu vector và dạng dữ liệu raster.
Phương pháp vector có khả năng biểu diễn topology (tính chất không gian) rất mạnh mẽ. Các yếu tố topology như mối quan hệ đỉnh (nodes), cạnh (edges), và mặt (faces) hoặc vùng (polygons) giữa các đối tượng được bảo toàn và có thể được mô tả chính xác. Chẳng hạn như biểu diễn các mối quan hệ chứa đựng (hồ nước trong công viên), ranh giới quốc gia, các tuyến đường giao nhau,... Còn trong raster, dữ liệu được biểu diễn bằng lưới các ô vuông (pixel), và mỗi pixel chứa một giá trị tại một vị trí cụ thể. Thích hợp hơn cho việc biểu diễn dữ liệu liên tục như độ cao, màu sắc, nhiệt độ...
Trong bài nghiên cứu này chúng tôi tiến hành phân tích chi tiết về 2 loại dữ liệu trên, sau đó tiến hành thực nghiệm trong bài toán land use – land cover. Với mục tiêu chọn ra dữ liệu phù hợp để có thể dự đoán được mục đích sử dụng đất và độ che phủ đất trong các năm tiếp theo. Việc này cho phép đánh giá xu hướng phát triển đô thị, mở rộng nông nghiệp, suy thoái môi trường. Ngoài ra có thể cung cấp thêm thông tin về tình trạng sử dụng đất hiện tại trong khu vực. Hữu ích cho việc lập kế hoạch sử dụng đất và quản lý tài nguyên. Theo dõi tình hình thay đổi sử dụng đất theo thời gian.
Bước đầu thực nghiệm cho thấy dữ liệu vector cho ra kích thước file nhẹ và tốc độ tính toán nhanh hơn, biểu diễn chính xác về ranh giới hành chính, độ dốc của địa hình. Tuy nhiên lại không thể biểu diễn các chi tiết phức tạp mà phải cần đến dữ liệu raster. Chẳng hạn như biểu diễn các thông số về độ cao, các phân tích không gian hay các công trình có độ phức tạp cao. Dữ liệu raster còn thể hiện ưu thế khi có thể tận dụng các mô hình xử lý hình ảnh, thống kê, biểu diễn dữ liệu có nhiều thuộc tính. Nhưng đánh đổi bởi kích thước lớn, thời gian xử lý và khó biểu diễn được có ranh giới hành chính một cách chính xác. Sau cùng, chúng tôi áp dụng vào mô hình học máy để so sánh độ chính xác giữa hai bộ dữ liệu. Kết quả dữ liệu raster cho hiệu quả dự đoán cao hơn với độ chính xác là 90% ở mô hình KNN.
Từ những ưu và nhược điểm trên, chúng tôi đề xuất hướng nghiên cứu mới về sự kết hợp của 2 dạng dữ liệu này với kỳ vọng mô hình mới có thể sở hữu được đặc trưng ưu việt của cả 2 dạng dữ liệu. Đặc biệt là trong khuôn khổ bài toán land use – land cover đang rất được chú ý hiện nay.
Trân trọng.
THÔNG BÁO Về kế hoạch giảng dạy, đăng ký học phần học kỳ 2 năm học 2018 – 2019
Kính gửi: Các bạn sinh viên UIT.
Theo kế hoạch năm học 2018 – 2019 đã được Hiệu trưởng phê duyệt, nhằm kịp thời chuẩn bị mở lớp và tổ chức cho sinh viên đăng ký học phần Học kỳ 2 năm học 2018 – 2019, Phòng Đào tạo Đại học (P.ĐTĐH) thông báo đến Quý Khoa, Bộ môn kế hoạch như sau:
- Ngày 28/11/2018: Phòng Đào tạo Đại học thông báo TKB (dự kiến)
- Sinh viên đăng ký học phần trên Website P.ĐTĐH http://daa.uit.edu.vn theo lịch:
- Đợt 1 (chính thức):
- Từ khóa 11 trở về trước: từ 9h00 ngày 18/12/2018 đến 16h00 ngày 22/12/2018.
- Khóa 12, 13: từ 9h00 ngày 20/12/2018 đến 16h00 ngày 22/12/2018.
- Đợt 2 (hiệu chỉnh): từ 9h00 ngày 25/12/2018 đến 16h00 ngày 29/12/2018.
- Đợt 3 (bổ sung): tuần đầu tiên của học kỳ 2, từ 9h00 ngày 18/02/2019 đến 16h00 ngày 23/02/2019.
- P. ĐTĐH công bố thời khóa biểu chính thức: ngày 21/01/2019
- Bắt đầu học kỳ 2 năm học 2018 – 2019: ngày 18/02/2019.
[BÀI VIẾT HAY - BÀI SỐ 3] BÀI TẬP GIỚI THIỆU NGÀNH CÔNG NGHỆ THÔNG TIN
Như ta biết, muốn xây một ngôi nhà, phần quan trọng nhất chính là phần móng nhà.Cũng giống như thế, đối với một sinh viên CNTT năm nhất thì việc quan trọng nhất là nắm vững khối kiến thức đại cương. Vì đây chính là nền tảng cơ bản mà mỗi người bắt buộc phải có để có thể đi sâu và nghiên cứu các môn chuyên ngành. Trong đó, 4 môn học quan trọng nhất chính là: Nhập môn lập trình, Anh văn,Giải tích và Pháp luật đại cương....
Nguyễn Hoài Phương - 21521308
Xem chi tiết tại đây.